Python 實現 RFM 用戶分析模型
RFM 是個簡易分析客戶價值的模型,在電商零售上常常使用。RFM 透過客戶近期的購買行為(Recency)、購買頻率(Frequency)、購買花費(Monetary) 三項指標評估客戶的價值狀況。
模型意義
- 最近一次消費(Recency):
上一次消費時間越近的顧客應該是比較好的顧客,對提供即時的商品或是服務也最有可能會有反應。 - 消費頻率(Frequency):
也就是常客,也可以說是客戶對品牌的忠誠度,頻率高的優於頻率低的客戶。 - 消費金額(Monetary):
客戶消費力,依循 Pareto’s Law (八二法則),80%的銷售額來自20%的客戶,高消費金額優於低消費金額。
長跪客戶分群意義
| Recency 消費時間 | Frequency 頻率 | Monetary 金額 | 客戶分群 |
|---|---|---|---|
| 近 | 高 | 高 | 高價值,VIP 客戶 |
| 遠 | 高 | 高 | 高價值,流失客戶 |
| 近 | 低 | 高 | 高價值,新客戶 |
| 遠 | 低 | 高 | 高價值,淺在客戶 |
| 近 | 高 | 低 | 一般價值,VIP 客戶 |
| 遠 | 高 | 低 | 一般價值,流失客戶 |
| 近 | 低 | 低 | 一般價值,新客戶 |
| 遠 | 低 | 低 | 一般價值,淺在客戶 |
以 R 與 F 分析圖劃分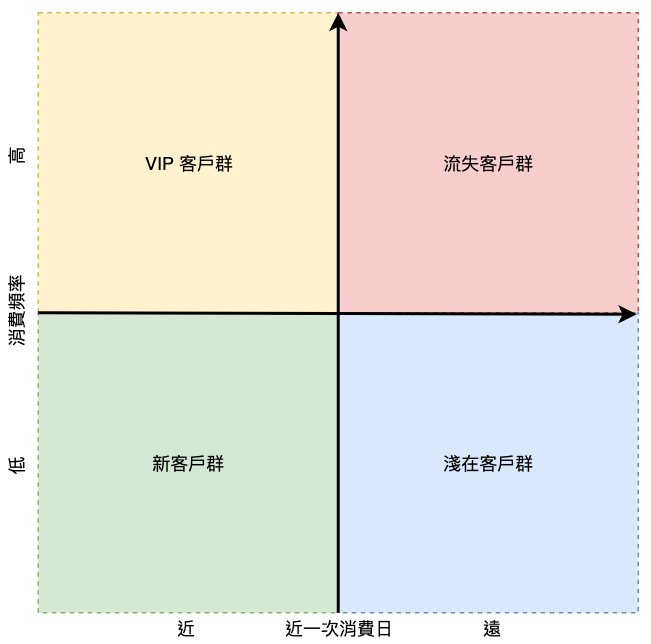
Python 程式碼
使用 kaggle 的資料做練習
Data Prepare
資料清理,排除缺失值與負值,並計算出收益。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
# Data Prepare
df = pd.read_csv('data.csv', encoding = "ISO-8859-1")
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate']) # 日期轉換
df_new = df.dropna() # 排除缺失值
df_new = df_new[df_new.Quantity > 0] # 排除負值
df_new = df_new[df_new.UnitPrice > 0] # 排除負值
df['Revenue'] = df['Quantity'] * df['UnitPrice'] # 收益計算
df['CustomerID'] = df['CustomerID'].astype('int64') # CustomerID 轉換
RFM Table
統計個人消費行為,得到至今最近一次消費的天數、消費次數、消費總金額
NOW = datetime(2011,12,10) # 資料最後一天為 2011/12/09
rfm_df = df.groupby('CustomerID').agg({
'InvoiceDate': lambda x: (NOW - x.max()).days, # 近一次消費天
'InvoiceNo': lambda x: x.nunique(), # 消費次數
'Revenue': lambda x: x.sum() # 消費金額
}).reset_index()
rfm_df.rename(
columns={'InvoiceDate': 'recency',
'InvoiceNo': 'frequency',
'Revenue': 'monetary'},
inplace=True
) # 重新命名
rfm_df['user'] = 1 # 繪圖計數用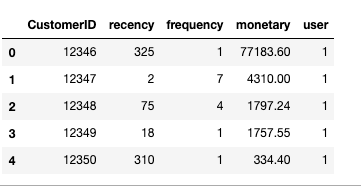
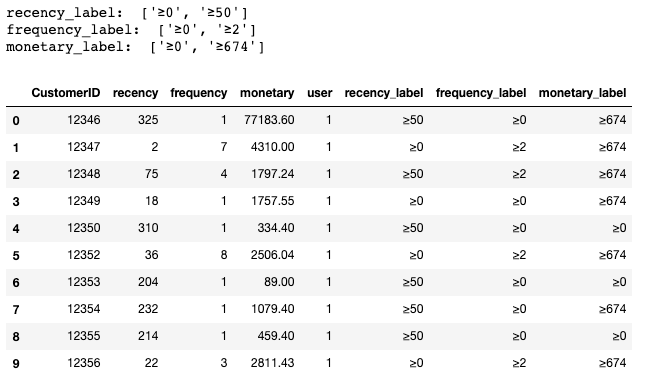
RFM Model
使用中位數(median)將數據分為兩級,也可以使用 33 與 66 分位(quantile)分三級
# 根據值將資料分級
# col_val: 輸入值, level: 分級級距
def get_level(col_val, level: list):
for idx, val in enumerate(reversed(level)):
if col_val >= val:
return f'≥{int(val)}'
# 分級
recency_level = [0, rfm_df['recency'].median()]
recency_label = [f'≥{int(i)}' for i in recency_level]
rfm_df['recency_label'] = rfm_df['recency'].apply(
lambda x: get_level(x, recency_level)
)
frequency_level = [0, rfm_df['frequency'].median()]
frequency_label = [f'≥{int(i)}' for i in frequency_level]
rfm_df['frequency_label'] = rfm_df['frequency'].apply(
lambda x: get_level(x, frequency_level)
)
monetary_level = [0, rfm_df['monetary'].median()]
monetary_label = [f'≥{int(i)}' for i in monetary_level]
rfm_df['monetary_label'] = rfm_df['monetary'].apply(
lambda x: get_level(x, monetary_level)
)
RFM Draw
利用 seaborn 繪圖,分成四個區塊為各個客戶群,裡面兩條長條圖分別為高消費力與低消費力的人數
g = sns.FacetGrid(
rfm_df, # 來源資料表
col="recency_label", # X資料來源欄位
row="frequency_label" , # Y資料來源欄位
col_order=recency_label, # X資料順序
row_order=frequency_label[::-1], # Y資料順序
margin_titles=True # 小圖啟用
)
g = g.map_dataframe(
sns.barplot, # 資料顯示的模式
x='monetary_label', # 小圖表X資料來源
y='user', # 小圖表Y資料來源,訪客計數
order=monetary_label, # X資料順序
estimator=sum, # Y計數加總
palette = sns.color_palette("muted") #畫布色調
)
g = g.set_axis_labels('Recency','Frequency').add_legend()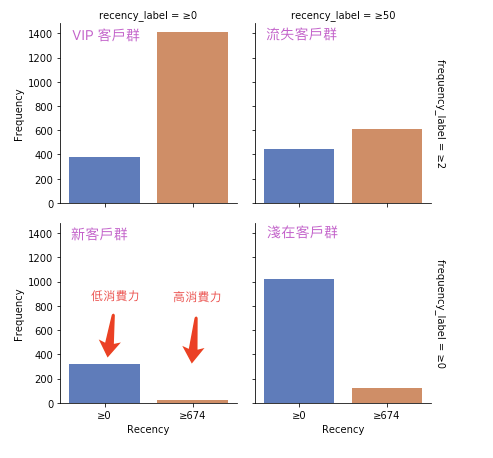
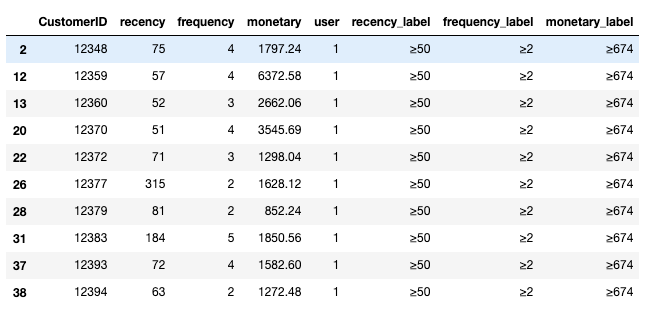
找出 VIP 客戶群
最後可以根據條件對不同客戶群分別做行銷
vip = rfm_df[
(rfm_df['frequency_label'] == frequency_label[-1]) &
(rfm_df['recency_label'] == recency_label[-1]) &
(rfm_df['monetary_label'] == monetary_label[-1])
]
vip.head(10)